2021. 9. 2. 03:34ㆍai/Machine Learning

machine Learning model이 어떤값을 예측하는가?
-Regression(회기) → continuous[계속되는] value
x(시간) - 1 3 5 8 , t(점수) - 5 15 70 100
-classification(분류) → discrete[별개의] value
Linear Regression(선형회기)을 확장해서 classification model을 만들어 볼꺼에요!!
x(시간) - 1 3 5 8 , t(점수) - F F F T
== Logistic[논리] Regression
초창기 인공지능(1960년대) 알고리즘'Perceptron[퍼셉트론]'을 발전시킨 개념
이는 뇌공학에서 따왔으며 이를 알고리즘으로 바꿨다/ 가치가있음 통과 아님 불통과
W1X1 W2X2 W3X3를 다 더한다 → Z→ 생긴게 계단이라 Step function : 값이 0보다크면1 작으면-1

1. W1X1 W2X2 W3X3 입력값이 오면 다 더한다 [Linear Regression] →
2. Z(continious value) : 1의 결과값 →
3. 이 위치에 나오는 함수 , 즉 linear regration의 결과에 적용하는 함수는 Activation[활성화] function
Activation function 의 종류 : sigmoid , Relu, tanh 등등..→
sigmoid 는 Activation function 의 대표적 함수로 x에 따라 y가 변환하는 함수로 y는 0 ~ 1
4. a(continious value) →
5. 임계함수 Threshold Function[결과값을 둘중하나로 분류, 연속값을 이상값으로 분류] (step function처럼 생겼다) →
6. `y [discrete value 분류값]
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# Logistic Regression을 다른 관점에서 한번 살펴보아요!
# 사용하는 Data Set은 mglearn이라는 module에서 가져다가 사용할께요!
# mglearn을 설치해 보아요!
import numpy as np
from sklearn import linear_model
import mglearn # 예를 들기 괜찮은 dataset이 있다
import matplotlib.pyplot as plt
import warnings # warning 출력을 하지 않기위해 import
warnings.filterwarnings(action='ignore') # warning이 출력되지 않아요!
# Training Data Set
x,y = mglearn.datasets.make_forge()
print(x) # x는 2차원 ndarray 2개의 column이 있어요. 0번째 column이 x좌표, 1번째 column이 y좌표
print(y) # x데이터로 표현되는 2차원 평면상의 점들이 각각 어떤값을 가지는지 알려주는 데이터.


mglearn.discrete_scatter(x[:,0], x[:,1], y)
#점을 찍어주는(scatter) 를 그래프로

model = linear_model.LinearRegression() # Linear Regression Model 생성
model.fit(x[:,0].reshape(-1,1), x[:,1].reshape(-1,1))
print(model.coef_, model.intercept_) # [[-0.17382295]] [4.5982984]
plt.plot(x[:,0], x[:,0]*model.coef_.ravel() + model.intercept_, color='r')
plt.show()
여기서 알수있는건 Logistic[논리] Regression 이 위 그림에서 선 이 판단기준이 될수있다 ?
22222222222222222222222222222222222222222222222222222222222222222222222222

Machine Learning의 결과 model이 어떠한 값을 예측하는가 ?
-Regression(회기) → continuous[계속되는] value
-classification(분류) → discrete[별개의] value
등 두가지 모델이 있다 . 두 모델중 어느것이든 구현하기 위해서 알고리즘을 사용할수 있는데
-Regression (Linear Regression, Logistic Regression) !!!!!!!!!!!!!!!! 위와 비교해서 주의 다른 Regression
-Sum
-Decision Tree
-Random Forest
-Neural Network 등등
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
Logistic Regression
1. training Data Set
2.Logistic Regression
(1)Linear Regression
(2)classification[분류] (activation function이용)
3.Threshold Function을 이용해서 결과값 출력

분류문제를 Linear Regression으로는 해결할 수 없나요? 네 해결할수 없어요
→ Logistic Regression으로 classificaion을 해결해야 해요!!
sigmoid (일반적으로 시그마라고 한다)


Linear Regression Model → y = Wx + b
최적의 w와 b를 구하기 위해 손실함수(loss function)을 미분해서 w,b 갱신


Logistic Regression Model → y = 1 / 1 + exp(-1, Wx + b)
Linear Regression loss function 에서 변경

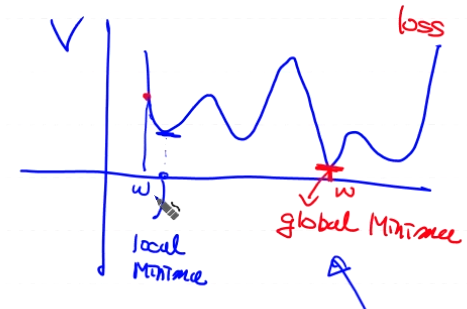
위 graph를 보면 알다싶이 Logistic Regression Model 은 gradient descent algorism이 적용이 안된다
왜냐하면 시작을 잘못 잡으면 local Minima가 최소로잡힐수 있기 때문이다
그래서 만든것이 아래와 같다


Cross Entropy , log loss - Logistic Regression Model 의 loss function
Cross Entropy 은 binaryClassfication(이진분류) , Multinomial Classfication(다중분류) 각각 다른식이다
Cross Entropy의 원래의미는 Multinomial Classfication(다중분류) 의 lossfunction이나 편의상 binaryClassfication(이진분류) 에도 사용

1. Training Data Set
2. Linear Regression
3. classification (Sigmoid)
4. Cross Entropy
5. loss가 최적확인
6. 최적이면 END 아니라면 Weight, bias update"편미분"
'ai > Machine Learning' 카테고리의 다른 글
| 분류 성능 평가 지표(Metric) (0) | 2021.09.03 |
|---|---|
| Logistic[논리] Regression 코드 (0) | 2021.09.03 |
| Tensorflow 1.대버전 (0) | 2021.09.02 |
| Nomalization(정규화),Multiple Linear Regression (다중선형회기) (0) | 2021.09.01 |
| Sklearn(사이키런), 이상치처리 (0) | 2021.08.31 |