2021. 8. 31. 02:18ㆍai/Machine Learning

저번에는 "python으로 구현" 하지만 상당히 어려워
python machine Learning Library를 사용하는데 그중 대표가 Sklearn(사이키런)
-Sklearn(사이키런)은 간단한 문제는 가능하나 복잡하거나 deep learning은 python코드로 사용
-python과 sklearn을 이용해 온도에 따른 ozone량 예측을 해보았으나 2가지 차 발견
-machine learning에서 학습이 잘되기 위해서는 data전처리가 필수!!
1.결측치 : nan
2.이상치(outlier) : data의 일반적인 값보다 상대적으로 큰 data = 전체 data 패턴에서 동떨어져있는 관측치
- 이런 이상치는 "평균"에 영향을 많이 끼치기 때문에 반드시 처리해야한다
- 독립변수 이상치 : 지대점, 지대값 / 종속변수 이상치 : outlier
이상치처리 방법 (수학적기법)
variance : 분산 , 정규분포로
likeilhood
NN
Density

이상치를 검출하기위해
- 사분위를 이용한 "Turkey Fence"
- 정규분포와 표준편차를 이용한"Z-score"
matplotlib같은 visualieation modul (시각화 모듈) 은 Boxplat기능을 제공
ㅇ (outlier 이상치)
Maximum (최고값)
3 사분위 (75%)
2사분위 (중위값, 50%)
1사분위 (25%)
Minimum (최솟값)
ㅇ (outlier 이상치)
IQR ( Inter quartile range ) : 1사분위와 3사분위 사이를 지칭
IQR value : 3사분위값 - 1사분위값
if "1사분위값 - (IQR value * 1.5)" 이 값보다 더 작은 값은 "이상치"
if "3사분위값 + (IQR value * 1.5)" 이 값보다 더 큰 값은 "이상치"
이렇게 이상치를 판단하는게 Turkey Fence
Tukey Fence
# 이상치 처리에 대해서 알아보아요!
import numpy as np
import matplotlib.pyplot as plt
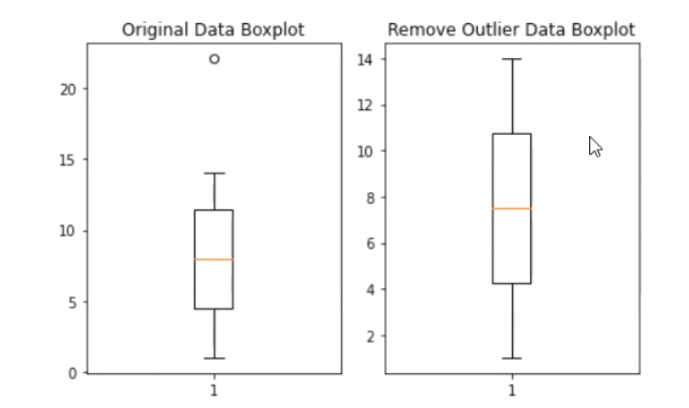
data = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,22.1])
fig = plt.figure() # 새로운 figure(도화지)를 생성
fig_1 = fig.add_subplot(1,2,1) # 1행 2열의 subplot에서 1번 위치
fig_2 = fig.add_subplot(1,2,2) # 1행 2열의 subplot에서 2번 위치
fig_1.set_title('Original Data Boxplot') # 제목을 쓸수있다 ( 한글은 안된다 )
fig_1.boxplot(data) # boxplot을 그린다

# 앗!! boxplot을 확인했더니 이상치가 있어요!!
# numpy로 사분위수를 구해보아요! np.percentile() 함수를 이용하면 되요!
print(np.percentile(data,25)) # 4.5 25 - 1사분위
print(np.percentile(data,50)) # 8.0 50 - 중위값
print(np.median(data)) # 8.0 중위값구하는 함수
print(np.percentile(data,75)) # 11.5 75 - 3사분위
iqr_value = np.percentile(data,75) - np.percentile(data,25) # 3사분위 - 1사분위
print('IQR_value : {}'.format(iqr_value)) # 7.0
upper_bound = iqr_value * 1.5 + np.percentile(data,75) # iqr_value * 1.5 + 3사분위
# upper_bound : 상계(上界): 주어진 집합의 어떤 원(元)보다도 크거나 같은 값; 예를 들면 3과 4는 1, 2, 3을 원(元)으로 하는 집합의 상계이다.
print('upper_bound : {}'.format(upper_bound)) # 22.0 보다 큰값은 이상치
lower_bound = np.percentile(data,25) - iqr_value * 1.5 # 1사분위 - iqr_value * 1.5
print('lower_bound : {}'.format(lower_bound)) # -6.0 보다 작은값은 이상치
# 우리 데이터에 대해 이상치를 출력하 세요!(boolean indexing)
print(data[(data > upper_bound) | (data < lower_bound)]) # [22.1]
result_data = data[(data <= upper_bound) & (data >= lower_bound)]
print('정제된 데이터 : {}'.format(result_data))
fig_2.set_title('Remove Outlier Data Boxplot')
fig_2.boxplot(result_data)
fig.tight_layout() # figure(도화지)의 간격을 알맞고 이쁘게 ?
plt.show()
Z-score
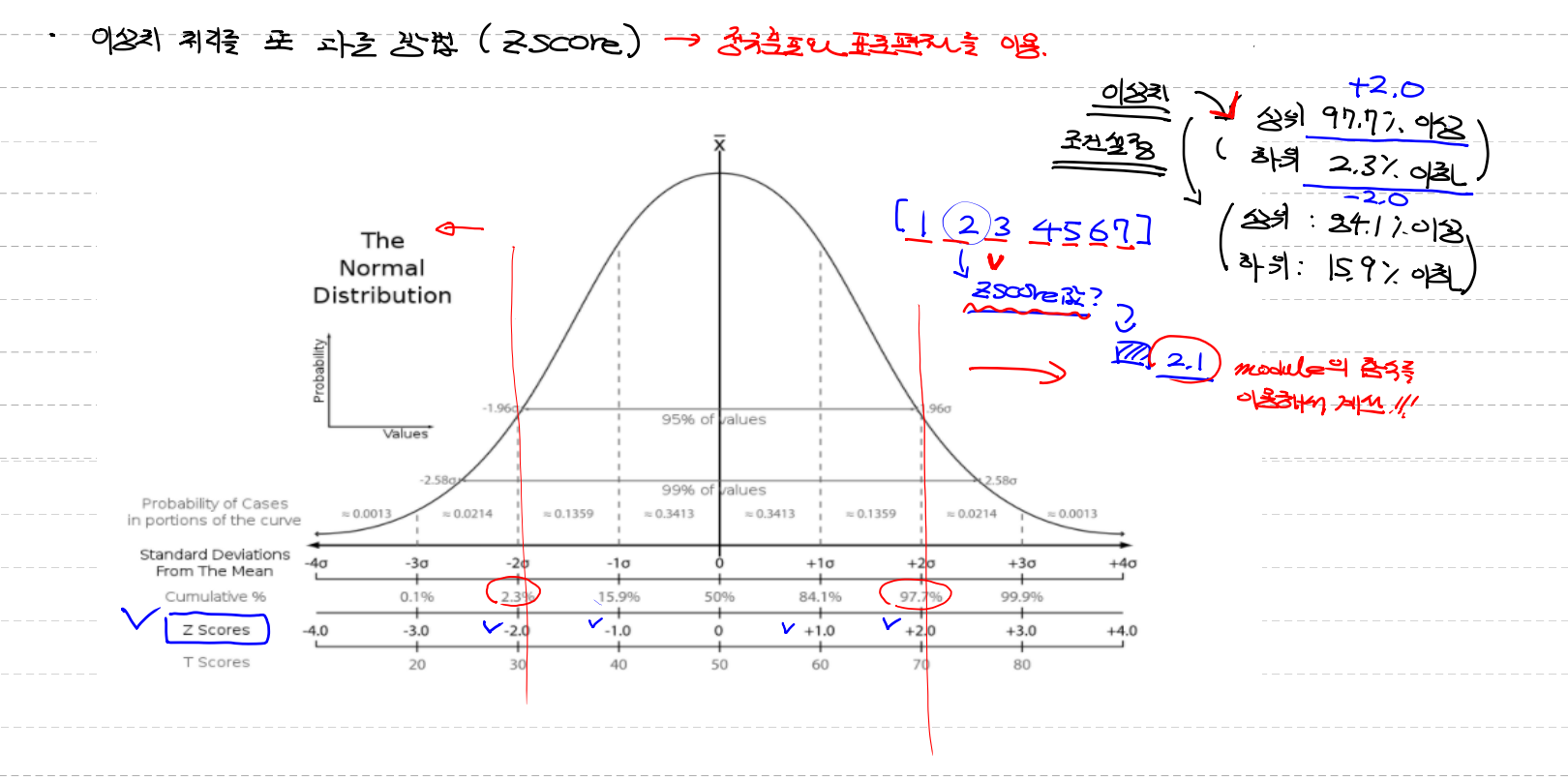
이상치를 처리하는 또 다른 방법(Z-score) → 정규분포와 표준편차를 이용
- data들을 정규분포로 나누어 data들의 각각을 z score로 나눈다 (modul의 함수를 이용해서)
상위 97.7% 이상 / 하위 2.3% 이하 (위 그림 빨간선)
상위 84.1% 이상 / 하위 15.9% 이하 와 같이 내가 기준점을 설정할수 있다
(위 사진에 z score라고 체크 되어있는곳 참고)
from scipy import stats (통계)
data = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,22.1])
zscore_threshould = 1.8 #zscore의 값을 설정
# 2.0을 많이 사용 (-1.8 이하, +1.8 이상)
# outlier를 출력
outlier = data[np.abs(stats.zscore(data)) > zscore_threshould] # 이상치값 구하기
stats.zscore() : zscore 를 구해라
np.abs() : 절대값으로 변경 (음수를 양수로)
# 이상치를 제거한 결과는
data[np.isin(data,outlier, invert=True)]
# np.isin : 여기안에 있니 ? 위는 data안에 outlier가 있니?
# invert=True # invert 역으로라는 뜻
Sklearn(사이키런)
import numpy as np
from sklearn import linear_model
# Training Data Set
# Supervised Learning(지도학습)
# dataset은 무조건 2차원 matrix
x_data = np.array([1,2,3,4,5]).reshape(-1,1)
t_data = np.array([3,5,7,9,11]).reshape(-1,1)
# linear regression object (선형회기) 를 생성
model = linear_model.LinearRegression() # 완성된 형태가 아닌 linear regression model이 생성
# 만들어진 model을 학습시켜요!
model.fit(x_data, t_data)
#.fix() 은 학습시키는 함수
# 학습된 Weight와 bias를 확인해 보아요! ( y = Wx + b )
print('Weight : {}, bias : {}'.format(model.coef_, model.intercept_))
# model.coef_ = W값
# model.intercept_ = b값
# prediction(예측)
print(model.predict([[20]]))
# x데이터를 주면 t데이터 반환
# 2차원으로 줘야한다

'ai > Machine Learning' 카테고리의 다른 글
| Tensorflow 1.대버전 (0) | 2021.09.02 |
|---|---|
| Nomalization(정규화),Multiple Linear Regression (다중선형회기) (0) | 2021.09.01 |
| ozone.csv를 python,sklearn으로 LinearRegression 처리 (0) | 2021.08.30 |
| LinearRegression 정리 (0) | 2021.08.30 |
| loss function(손실함수), Gradient Desert Algorithm(경사하강법) (0) | 2021.08.30 |