2021. 8. 30. 01:26ㆍai/Machine Learning
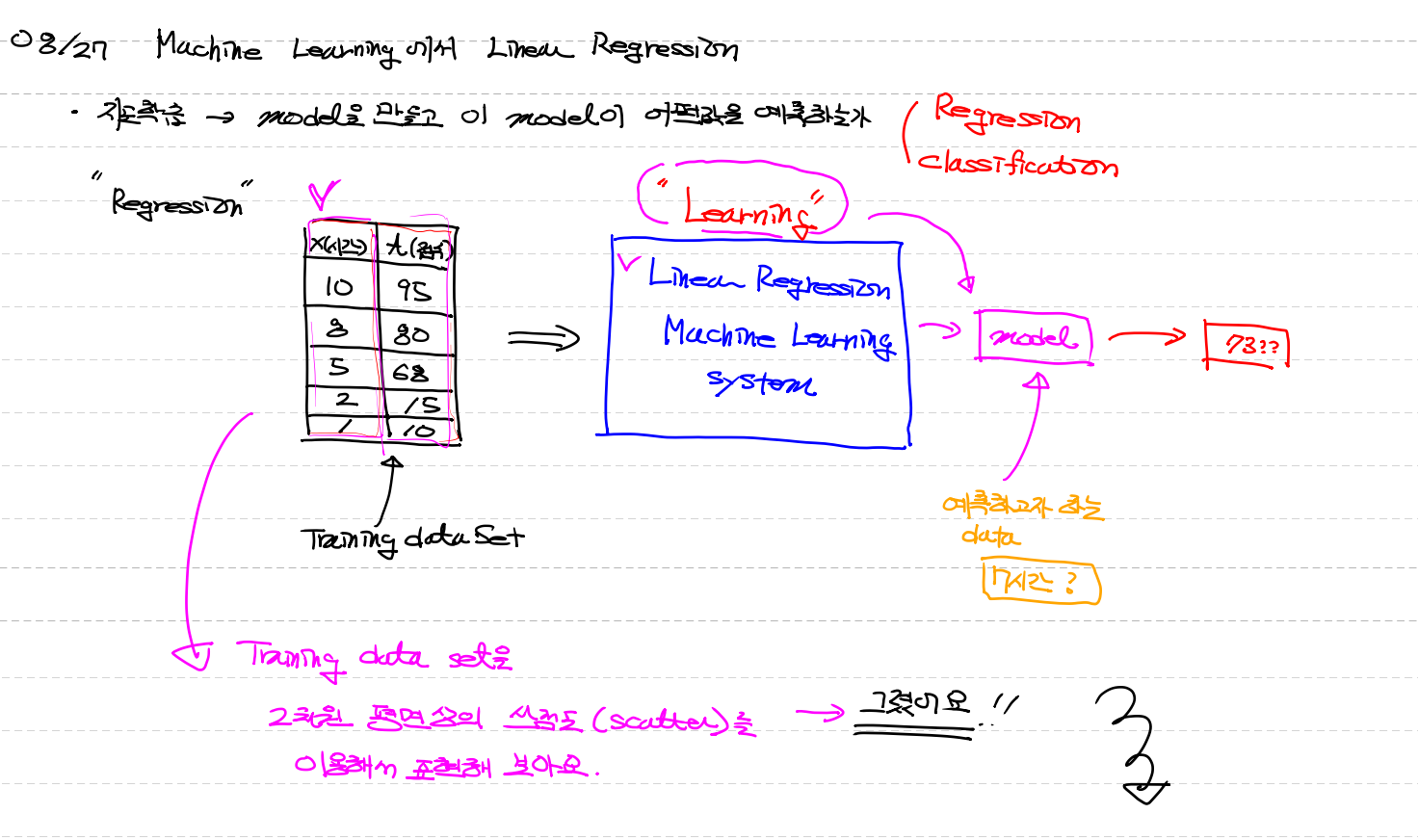
!! Machine Learning 에서 Lineal Rrgression(선형회기)
scatter(산점도) : 우리가 가진 data의 분포확인을 위해 점을 찍어
어떻게 분포되어있나 2차원 평면상(x,y축) 보이는 그래프 / data가 많고 복잡할때 점으로 보여 유용하다
지도학습 → model을 만들고 이 model이 어떤값을 예측하는가
-Regression (연속적인 값 예측)
1. training data set
2. Lineal Regraession (선형회기) Learning
3. Model
4. 예측하고자 하는 data 입력
5. 예측결과값 반환
-classification(참 거짓, 합격 불합격 등..)
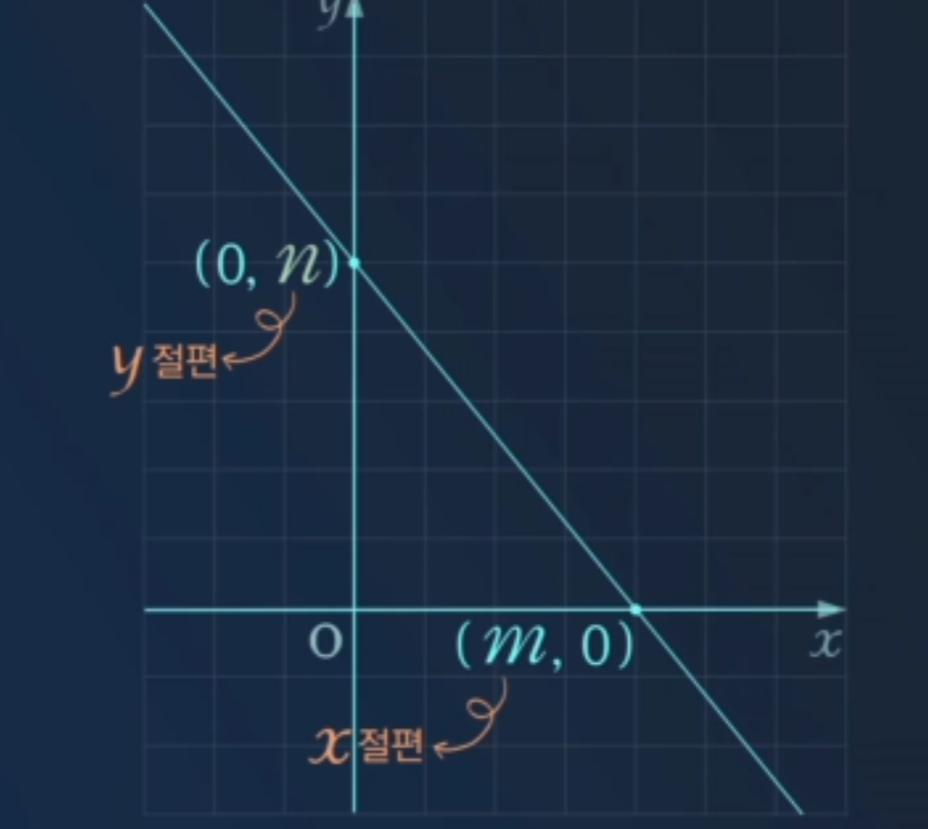

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'공부시간(x)' : [1,2,3,4,5,7,8,10,12,13,14,15,18,20,25,28,30],
'시험점수(t)' : [5,7,20,31,40,44,46,49,60,62,70,80,85,91,92,98,99]
})
plt.scatter(df['공부시간(x)'], df['시험점수(t)'])
# plt.scatter : 산점도 그리는 명령어

# 우리는 y=ax+b 형태의 모델을 만들어야 해요!
# plt.plot : 점을 이어서 직선을 그리는 명령어
# plt.plot(df['공부시간(x)'],df['공부시간(x)']*2 + 3, color='r')
plt.plot(df['공부시간(x)'],df['공부시간(x)']*5 - 7, color='g')
# plt.plot(df['공부시간(x)'],df['공부시간(x)']*1 + 8, color='b')
# plt.plot(df['공부시간(x)'],df['공부시간(x)']*4 - 10, color='magenta')
plt.show()


y = ax (기울기) + b(절편 : y축과 만나는 점) (독립변수1개)를 좁혀가면서 찾아가는 학습 → Simple Lineal Regression(단순선형회기)
= 독립변수가 1개라 직선이 1개
[a와 b에 따라 다양한 직선이 나올수 있어요]
machine Learning에서는 직선을 표현할때
y = wx + b
( w(weight) : 가중치 )
( b(bias) )
w, b 어떤 직선이 더 적합한지 찾기 위해 error(오차) 를 이용

오차(error) :
실제값(t) - 점 , 계산된값(y) - [5x -7 ] 의 차이를 오차
즉 error는 t - y (Wx + b)
error의 값이 크다면 직선이 데이터를 잘 표현하지 못하고 있다는 의미 = 점과 선의 거리가 크다면
(오차는 작으면 작을수록 좋다)
즉 Error의 합이 최소가 되는 W 와 B를 찾아야한다
이를 위해 loss funtion(손실함수) = cost function(비용함수)를 이용

Loss Function (손실함수) = cost function(비용함수) : Training Data Set의 정답 (lable , t)과 우리의 Model (예측값 [y=Wx+b] )을 더해서 수식으로 표현한 것
그런데 error에 부호(+,-)가 있어요 → 부호를 날리고 절대값을 이용하려고
오차의 제곱의 평균을 이용 = 평균제곱오차 (MSE : Mean Squared Error)
우리의 목적은 Loss function의 값이 최소가 되게하는 W, b를 구하는 것.
→ 최소제곱법( Least squared Method )을 이용해서
loss 함수를 수학적으로 표현해 보아요 !!

Loss function을 수식으로 풀어보아요 !
t (lable, 입력값, 사실값) , y = Wx + b (model, 예측값)
loss function은 E 라고 표현한다
=> 우리의 목적은 loss 함수를 최소로 하는 W,b를 구해서 model을 완성하기 위해서 알고리즘 이용
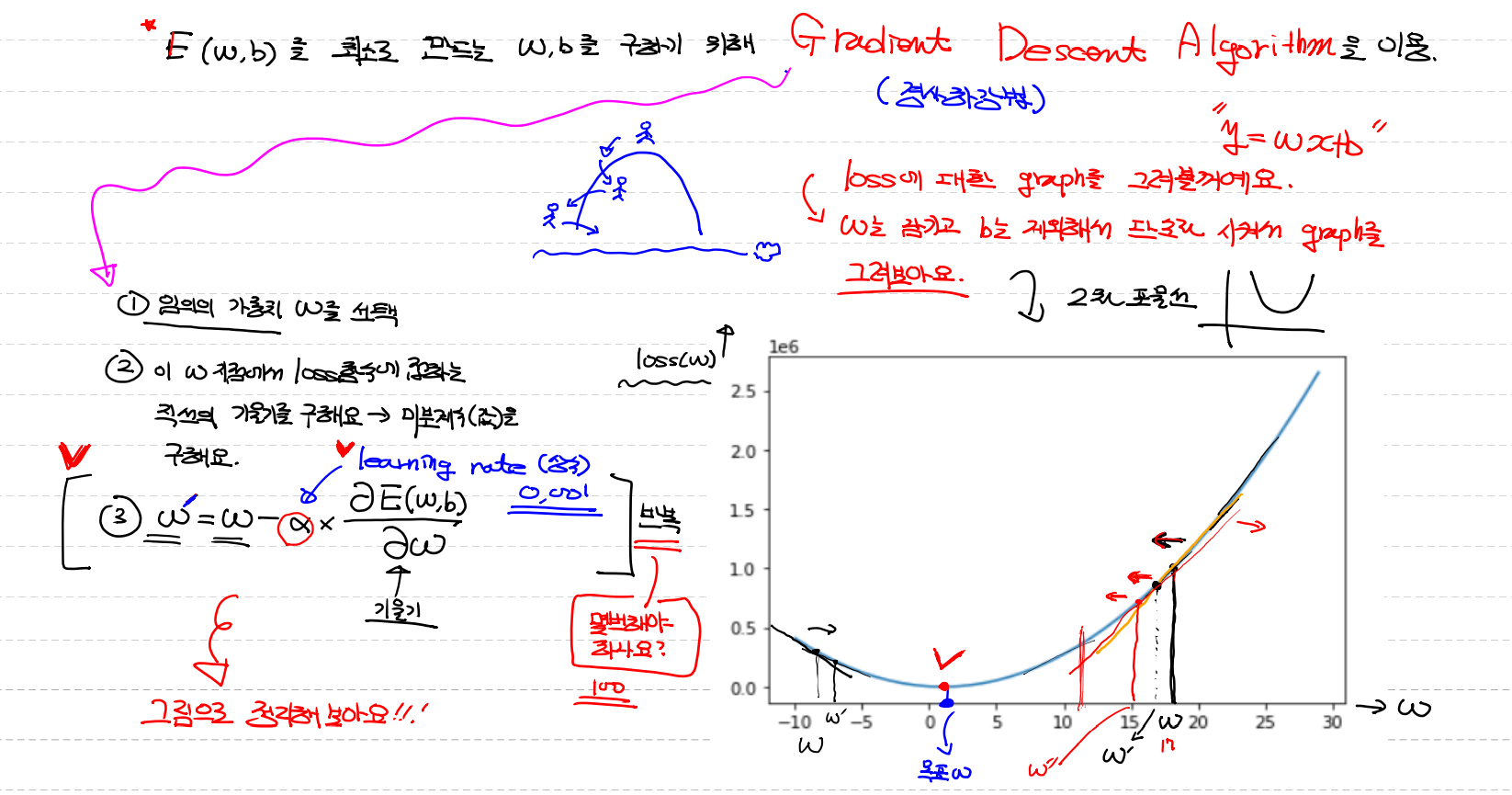
E(w,b)를 최소로 만드는 w,b를 구하기 위해 Gradient Desert Algorithm(경사하강법)을 이용
Gradient Desert Algorithm(경사하강법) : 산에서 경사가 제일 급한 곳으로 찾아간다고 생각하면 된다
loss에 대한 graph를 그려볼꺼에요 → w(계수)는 남기고 b(상수값)는 제외시켜 graph를 그릴거에요 (밑 코드)
1.임의의 가중치 w를 선택
2.임의의 w지점에서 loss함수에 접하는 접하는 직선의 기울기를 구해요 → 미분계수 (값)을 구해요
3.

위에서 a 는 learning rate(상수) / a는 내가 custommizing 해야한다 일반적으로는 0.001이 될때까지
[너무크면 답을 건너뛰고, 너무작으면 반복횟수가 많아 오래걸린다]
반복 횟수또한 내가 custommizing해야줘야한다

# loss function의 대략적인 모습을 알아보기 위해 그래프를 그려보아요!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# training data set
# 독립변수가 1개인 경우에 대해서 알아보고 있어요!
x = np.arange(1,101)
t = np.arange(1,101)
W = np.arange(-10,30)
loss = [] # W에 대해서 loss값을 계산해서 W와 loss함수의 그래프를 그래볼꺼예요!
for tmp in W:
loss.append(np.power((t-tmp*x),2).mean())
plt.plot(W,loss)
plt.show()

ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
정리 (독립변수 1개인 단변수)
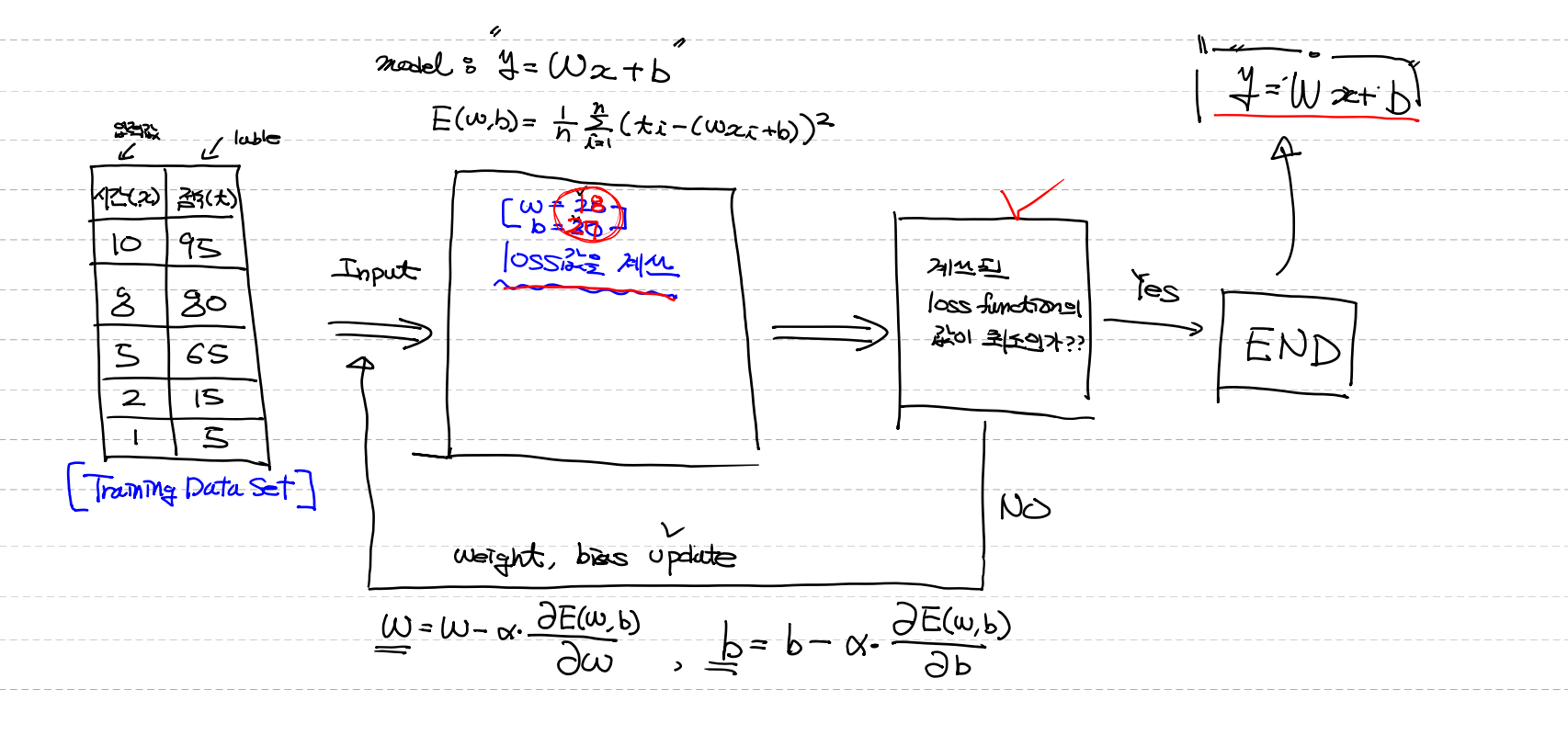

1. Training data set 준비
2. hypothests(가설) : 완성되지 않고 앞으로 만들어 가는 놈, 앞으로 만들 모델
model을 정의 : y = Wx + b(1차원) => X ` W + b
3. loss 함수정의 - (w와 b를 랜덤으로?)

4. learning rate(상수값)설정
5. Gradient Descent algorithm을 이용한 반복학습
6.

해서 w 와 b값 update
7. 최솟값이 종료될때까지 반복
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# python을 이용해서 간단하게 구현해 보아요!
import numpy as np
# 1. Training Data Set 준비
x_data = np.array([1,2,3,4,5]).reshape(5,1)
t_data = np.array([3,5,7,9,11]).reshape(5,1)
# 2. Weight & bias를 정의
W = np.random.rand(1,1)
b = np.random.rand(1)
# 3. loss function 구현
def loss_func(input_value):
# input_value에는 W와 b의 값이 들어가 있어요! => [W의 값, b의 값]
W = input_value[0].reshape(1,1)
b = input_value[1]
# model
# y = XW + b
y = np.dot(x_data,W) + b
return np.mean(np.power(t_data-y,2))
# 4. 미분을 수행할 함수
# loss function을 미분하기 위해 편미분 사용(f는 loss함수, x는 w, b)
def numerical_derivative(f, x):
# f : 미분을 하려고 하는 함수
# x : 모든 독립변수의 값을 포함하고 있는 ndarray(차원에 무관하게 처리할 수 있어야 해요!)
delta_x = 1e-4
derivative_x = np.zeros_like(x) # [0.0 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index
tmp = x[idx] # x : [1.0 2.0] , tmp = 1.0
# 중앙차분으로 수치미분하는 식 : (f(x + delta_x) - f(x-delta_x)) / 2 * delta_x
x[idx] = tmp + delta_x # x : [1.0001 2.0]
fx_plus_deltax = f(x)
x[idx] = tmp - delta_x # x : [0.9999 2.0]
fx_minus_deltax = f(x)
derivative_x[idx] = (fx_plus_deltax - fx_minus_deltax) / (2 * delta_x)
x[idx] = tmp # x : [1.0 2.0]
it.iternext()
return derivative_x
# 5. learning rate 정의
learning_rate = 1e-4
# 6. 반복 학습을 진행해 보아요!
for step in range(100000):
# 최적의 loss값인가요? => 판단하는게 쉽지 않아요!
input_param = np.concatenate((W.ravel(), b.ravel()), axis=0) # [W의 값, b의값]
tmp = learning_rate * numerical_derivative(loss_func,input_param) # [W의 편미분값, b의 편미분값]
W = W - tmp[0].reshape(1,1)
b = b - tmp[1]
if step % 10000 == 0:
print('W의 값은 {}, b의 값은 : {}'.format(W,b))
# 수행시키면 W와 b의 값이 생성이 되요!

predict_value = np.array([[7]])
H = np.dot(predict_value,W) + b # Hypothesis(Model)
print(H)

'ai > Machine Learning' 카테고리의 다른 글
| ozone.csv를 python,sklearn으로 LinearRegression 처리 (0) | 2021.08.30 |
|---|---|
| LinearRegression 정리 (0) | 2021.08.30 |
| 편미분, Regression(회기) (0) | 2021.08.28 |
| 미분 (0) | 2021.08.27 |
| Machine Learning 기본 (2) | 2021.08.25 |