2021. 10. 5. 00:38ㆍai/Deep Learning

이전에 작업한 "MNIST"는 gray-scale 이었어요
→ 속도도 빠르고 단순한 image였기 때문에 (convolution layer3개)+(pooling layer)+(FC layer)
= 높은정확도(99%) = GPU가 아닌 CPU (1시간이내)
하지만, 실무에서 사용하는 데이터(image)는
(1) size가 커요 + color = 1개 image의 용량이 크고 학습도 잘 안되요
(2) convolution Layer, pooling layer 가 많이필요해서 시간↑
(3) cpu로는 학습이 안되요! → gpu를 사용 (그래도 오래걸려요)
→ hyperparameter(내가 조절하는 작업들)을 하기 위해 상당히 오랜시간이 걸릴수 밖에 없어요!!
→ pretrained network을 이용하면 좋아요!!
(기존에 이미 학습이 끝나서 완성된 Model [Nevral Network]을 이용) → Transfer Learning (전이학습)
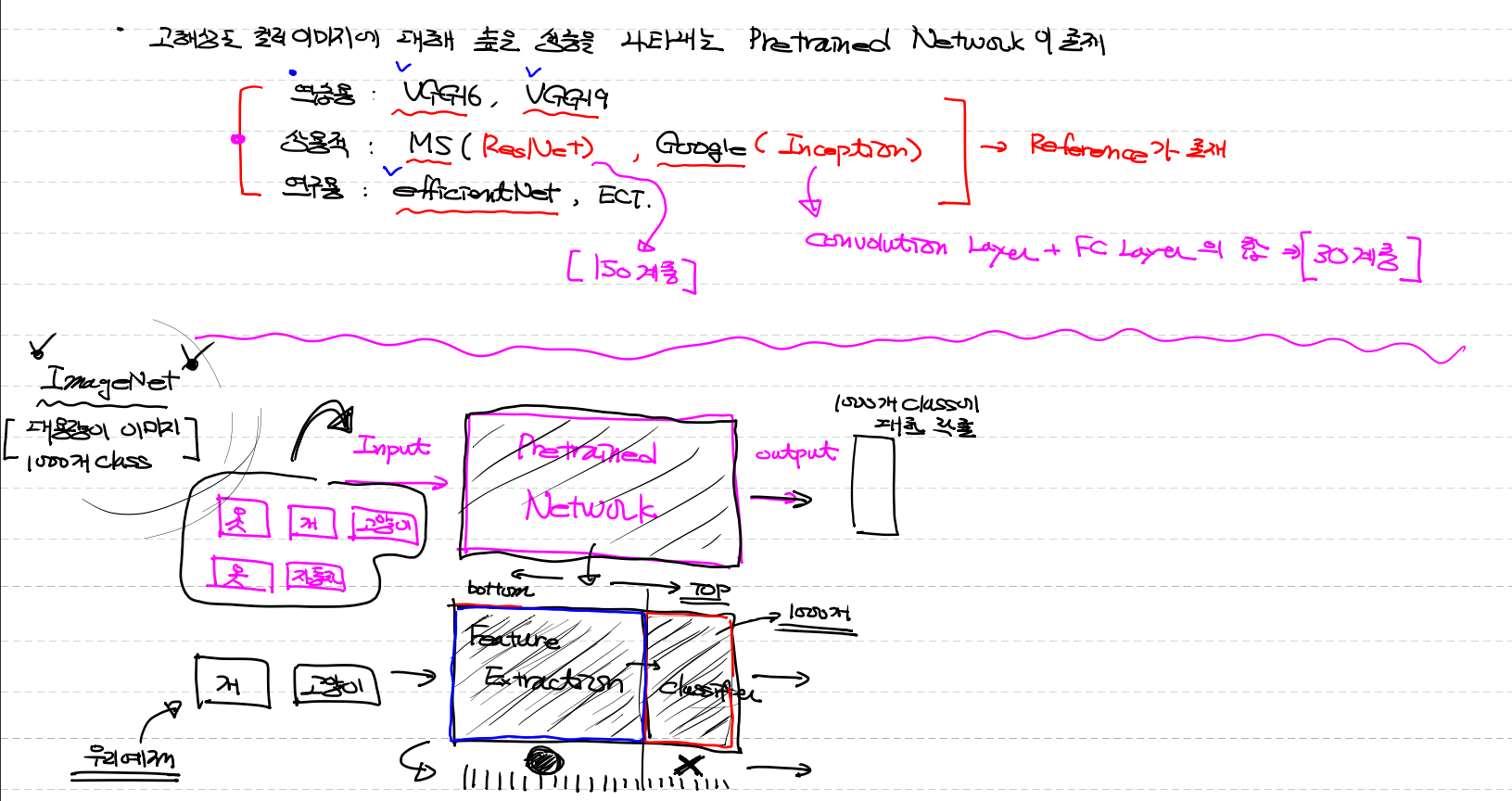
고해상도 컬러이미지에대해 높은 성능을 나타내는 pretrained Network이 존재
연습용 : VGG16, VGG19 # 숫자는 Layers의 수
상용적 : ResNet (MS), Inception (Google) → Converution Layer, FC Layerd의 합 : 각각 150계층, 30계층
연구용 : efficientNet , ECT
= 위 모두 Reference(참고) [각각 사용하는 방법]가 존재
"ImageNet" [대용량 이미지 ,1000개 class]
input → Pretrained Network → output
1000개의 class에 대한 확률
- Pretrained Network
(1) Feature Extraction
(2) Classifier
ImageNet이 사용하는 classifier는 못써서 Feature Extraction만 사용해서 특성만 뽑는다
model = VGG(include_top=False) 를 줄수 있는데
여기서 top은 classfier
bottom 은 Feature Extraction
# Pretrained Network을 가져와서 확인해보아요!
# Pretrained Network의 종류는 상당히 많아요!
# (VGG16, VGG19, ResNet, Inception, EfficientNet, MobileNet, 등등등)
# tensorflow.keras안에서 제공되는 VGG16을 이용해 보아요!
from tensorflow.keras.applications import VGG16
model_base = VGG16(weights='imagenet', # 어떤 data를 기반으로 만들었냐
include_top=False, # top은 classfier
input_shape=(150,150,3)) # 들어갈때의 크기
# model_base = VGG16(weights='imagenet',
# include_top=True)
# # (224, 224, 3)
print(model_base.summary())
# 이렇게 Pretrained Network을 가져다 사용할 수 있어요!
# 이제 두가지 선택지가 존재!
# 1. 우리가 가지고 있는 이미지(개와 고양이-4000개)를 Convolution layer(VGG16)에 통과
# 특성을 추출한 이미지(Feature Map)가 나와요! => (None, 4, 4, 512)
# 이 결과를 가지고 FC Layer를 이용해서 학습시키는거예요!
# 장점 : 빨라요!(filter를 update할 필요가 없어요!, classifier(DNN)만 학습하면 되요! )
# 2. VGG16에 Dense Layer를 붙여서 전체 network을 확장시켜서 사용
# 학습하기 위해 우리의 데이터가 항상 convolution layer를 통과해요 => 속도가 느려져요!
# 우리가 가지고 있는 이미지(개와 고양이-4000개)를 Convolution layer(VGG16)에 통과
# 특성을 추출한 이미지(Feature Map)가 나와요! => (None, 4, 4, 512)
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
model_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150,150,3))
train_dir = '/content/drive/MyDrive/융복합 프로젝트형 AI 서비스 개발(2021.06)/09월/30일(목요일)/cat_dog_small/train'
valid_dir = '/content/drive/MyDrive/융복합 프로젝트형 AI 서비스 개발(2021.06)/09월/30일(목요일)/cat_dog_small/validation'
test_dir = '/content/drive/MyDrive/융복합 프로젝트형 AI 서비스 개발(2021.06)/09월/30일(목요일)/cat_dog_small/test'
datagen = ImageDataGenerator(rescale=1/255)
batch_size = 20
# directory : ImageDataGenerator로 Image를 가져올 폴더(디렉토리)
# sample_count : directory안에 있는 Image의 개수
def extract_feature(directory, sample_count):
# 이 함수의 결과는..각 이미지의 특성을 뽑아낸 Feature Map이 나와야 해요!
# 해당 이미지의 label도 결과로 나와야 해요!
features = np.zeros(shape=(sample_count,4,4,512))
labels = np.zeros(shape=(sample_count,))
generator = datagen.flow_from_directory(
directory,
target_size=(150,150),
classes=['cats', 'dogs'],
batch_size=batch_size,
class_mode='binary'
)
i = 0
# x_data : 20장의 이미지 픽셀 데이터, t_data : 20장의 레이블
for x_data, t_data in generator:
feature_batch = model_base.predict(x_data)
features[i*batch_size:(i+1)*batch_size] = feature_batch
labels[i*batch_size:(i+1)*batch_size] = t_data
i += 1
if i * batch_size >= sample_count:
break
return features, labels
train_feature, train_label = extract_feature(train_dir,2000)
valid_feature, valid_label = extract_feature(valid_dir,1000)

# 위의 결과로 feature map과 label에 대한 이미지 특성 데이터를 확보
# 이렇게 얻은 데이터로 DNN 해야 해요!
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(Dense(units=256,
activation='relu',
input_shape=(4*4*512,)))
model.add(Dropout(rate=0.5))
model.add(Dense(units=1,
activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate=1e-5),
loss='binary_crossentropy',
metrics=['accuracy'])
train_feature_result = np.reshape(train_feature,(2000,4*4*512))
valid_feature_result = np.reshape(valid_feature,(1000,4*4*512))
histroy = model.fit(train_feature_result,
train_label,
epochs=30,
batch_size=20,
validation_data=(valid_feature_result, valid_label),
verbose=1)

# accuracy와 loss 비교
import matplotlib.pyplot as plt
train_acc = histroy.history['accuracy']
valid_acc = histroy.history['val_accuracy']
train_loss = histroy.history['loss']
valid_loss = histroy.history['val_loss']
fig = plt.figure()
fig_1 = fig.add_subplot(1,2,1)
fig_2 = fig.add_subplot(1,2,2)
fig_1.plot(train_acc, color='b', label='training_accuracy')
fig_1.plot(valid_acc, color='r', label='validation_accuracy')
fig_1.legend()
fig_2.plot(train_loss, color='b', label='training_loss')
fig_2.plot(valid_loss, color='r', label='validation_loss')
fig_2.legend()
plt.tight_layout()
plt.show()

'ai > Deep Learning' 카테고리의 다른 글
| Fine Tuning (미세조정) , EarlyStopping, ModelCheckpoint (0) | 2021.10.05 |
|---|---|
| Data Augmentation (데이터 증식) (0) | 2021.10.01 |
| Image Data Generator (cat & dog ver) (1) | 2021.10.01 |
| cat & dog tf2.0 ver (0) | 2021.09.30 |
| Dog & Cat img → csv (0) | 2021.09.30 |