2021. 9. 28. 09:01ㆍai/Deep Learning

1.
- convolutional Neral Network (CNN) - 합성곱 신경망
==convnet(컨브넷)이라고 부르기도 한다 (줄임말)
- DNN (Deep Nevral Network) == 과거 Deep learning
- FC Layer (Fully connected Layer) == Dense : 모든 node들이 연결된 Layer
- Flatten : 이미지가 나오면 3차원 4차원인데 2차원으로 평평히 펴준다는 의미 / DNN의 input layer라고 생각
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
번외 :구글,ibm,ms 같은데는 convolution layer가 128개? 정도된다
CNN의 구조
1. traning Data Set (X, T)
2. input layer (전달역할)
3. convolution layer
(1) 합성곱 작업
(2) relu (activation)
(3) pooling layer [선택]
4. (3번작업 !!)
5. (3번작업 !!)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ여기까지 특징 / 이제부터 DNN(학습)
6. flatten layer (4차원에서 2차원으로 펴준다)
(hidden layer는 선택이나 일반적으로 사용x 연산만 많아지고 복잡해져서)
7. output layer
(1) linear regression
(2) softmax
8 loss계산
(1) no면 반복학습작업 : filter의 값을 update
(2) yes면 끝
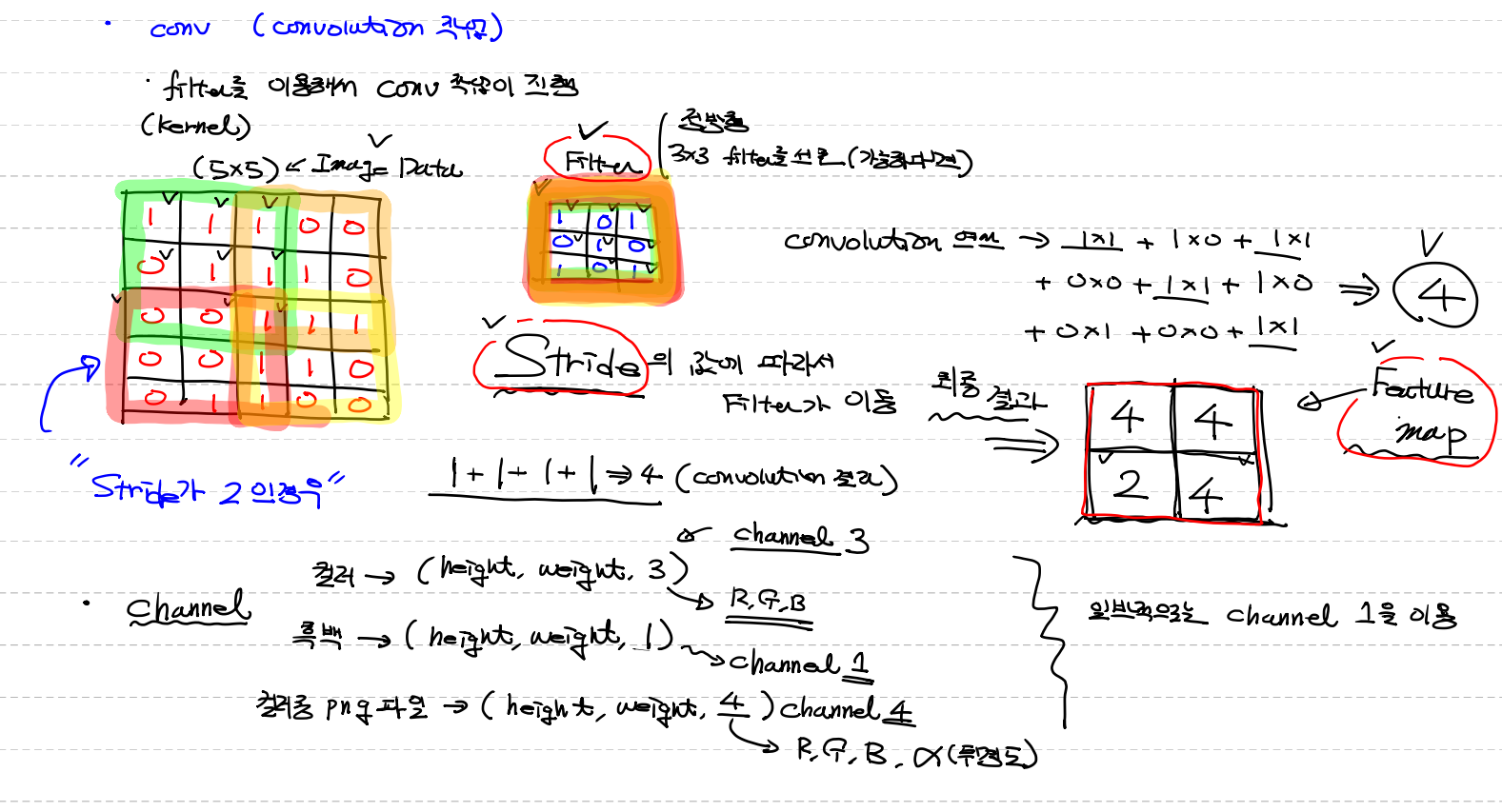
conv (convolution 작업)
- filter를 kernel이라고도 한다
- filter는 정방향 (정사각형 4x4, 5,5와 같이)
- filter 는 작을수록 좋다 (주로 3x3을 선호 왜냐하면 이미지의 크기랑 맞추기위해)
- filter의 처음값은 랜덤
- Feature map : image data와 filter 의 합성곱 결과값
filter를 이용해서 conv작업이 진행
1. (5x5) image data / (3x3) filter
2. image data 크기에 맞춰 filter와 합성곱
3. stride2 (주로 1)의 값에 따라서 filter가 이동
- 작게 움직일수록 효율적 / 그러나 이미지가 크면 1보다는 크게
4. feature map
channel =이미지의 컬러값 / 2차원 다음의 차원
- 일반적 channel
컬러 (height, weight, channel 3 = RGB)
흑백 (height, weight, channel 1)
컬러중 png파일 → (height, weight, channel 4 = RGBa(투명도) )
일반적으로는 channel 1을 이용
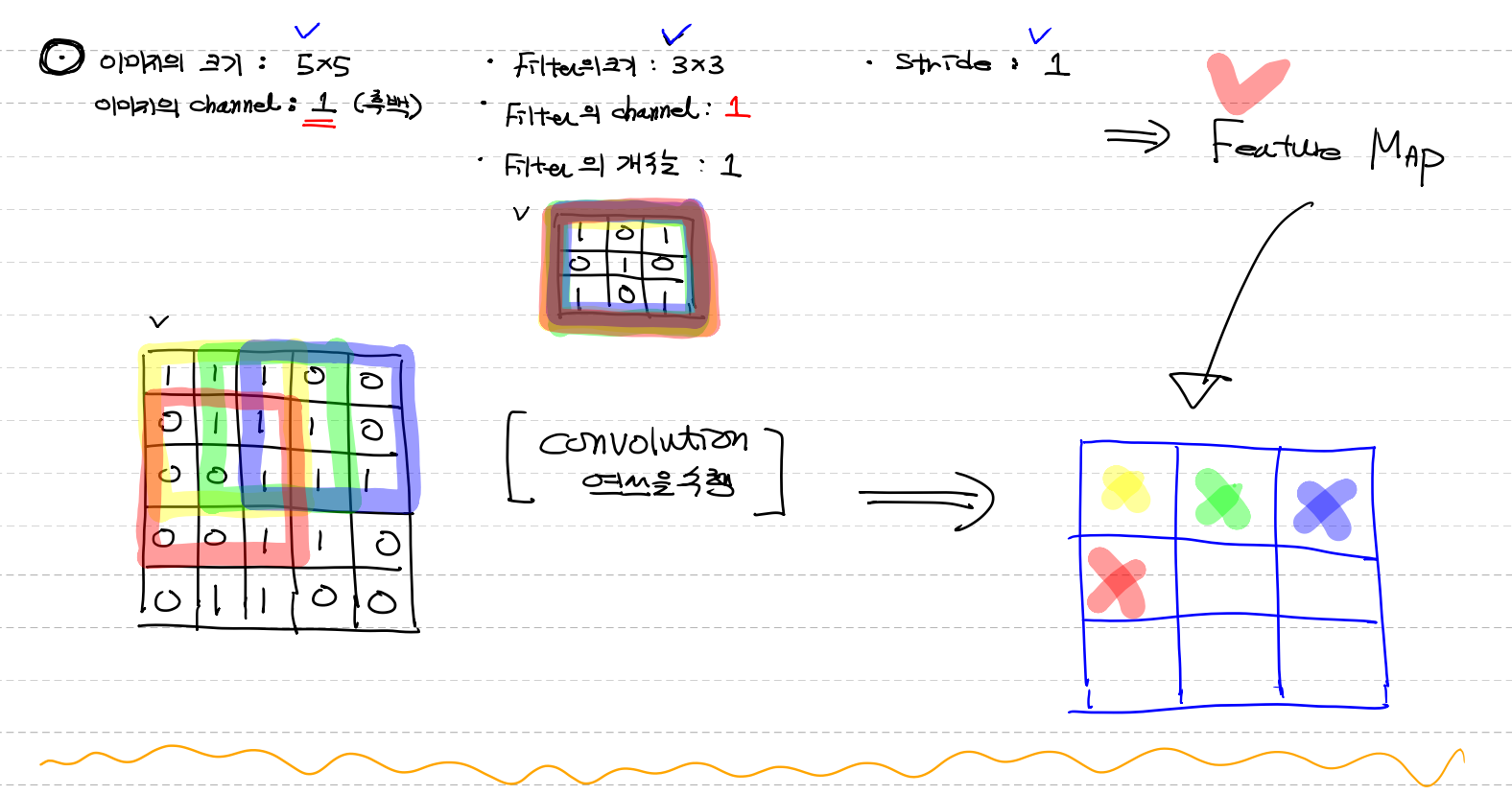
이미지의 크기 : 5x5
이미지의 channel : 1 (흑백)
filter의 크기 : 3x3
filter의 channel : 1 (이미지 channel의 맞춰)
filter의 갯수 : 1 (여러개 쓸수도 있다)
stride : 1
→→ convolution연산을 수행해서 나온값이 Feature map (3x3)
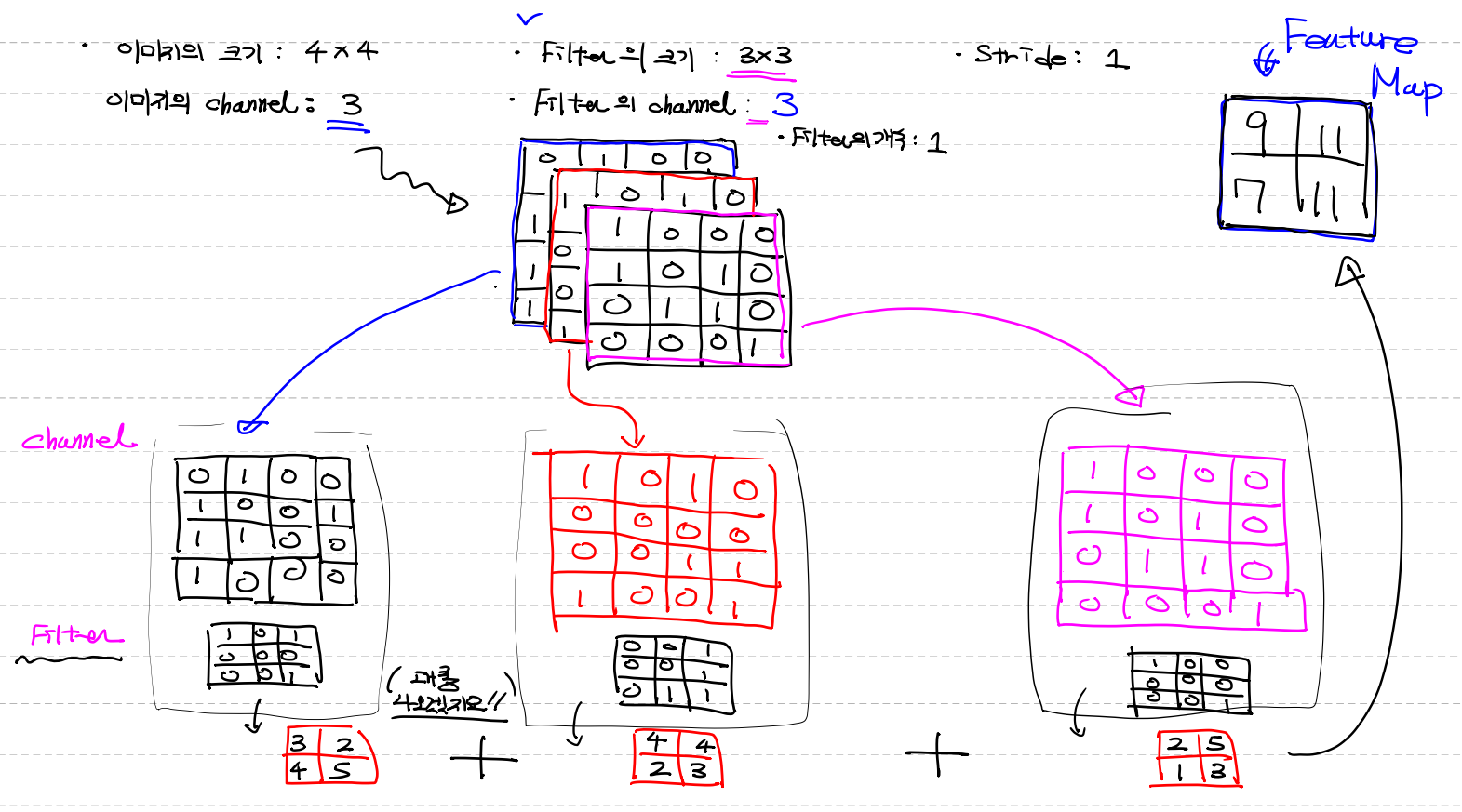
이미지의 크기 : 4x4
이미지의 channel : 3 (컬러) (이미지가 3장이 곂쳐있다)
filter의 크기 : 3x3
filter의 channel : 3
- 이미지 channel마다 filter를 주기위해 이미지의 channel과 같아야한다
- 각 이미지마다 filter의 값은 다르다
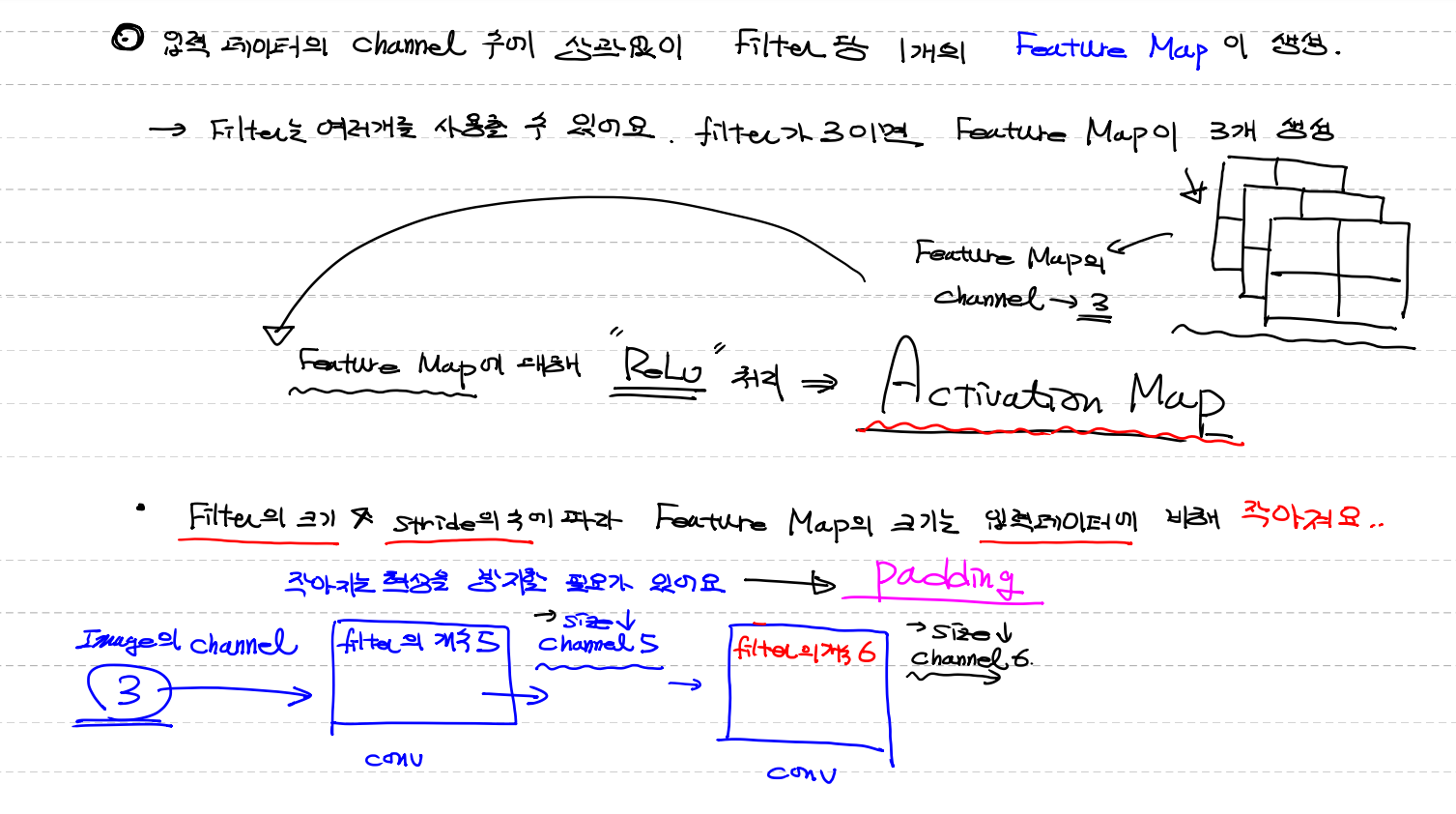
입력 데이터의 channel 수에 상관없이 filter당 1개의 Feature Map이 생성
- filter는 여러개를 사용할 수 있어요 .
- filter가 3이면 feature Map이 3개 생성 = feature map의 channel이 3개
- Relu처리를 통해 feature map이 몇개든 1개의 activation map 생성
→ 각 feautre map에 대해 "Relu"처리 해서 나온 결과 == Activation Map
- filter크기, stride수에 따라 Feature map의 크기는 입력데이터에 비해 작아져요
→ 작아지는 현상을 방지할 필요가 있어요 이때 padding 사용
1. image channel 3
2.(conv) filter의 개수 5
(사이즈는 줄고 channel 5)
3.(conv) filter의 개수 6
(사이즈는 더 줄고 channel 6)

padding : 덧붙이다 (zero padding) / 0을 덧붙이면 이미지에 영향을 받지 않는다
정의 : 입력데이터 외각(위,아래,좌,우)에 지정한 pixel만큼 특정값(0) 으로 채우는 작업
ex) 3x3 을 1개씩 늘리면 5x5가 된다
code로 표현할때는
- valid option : padding 처리를 하지 않아요
- same option : zero padding 처리를 해요
몇개를 덧 붙일지는 알아서해요 →
입력과 출력의 크기가 같도록 설정 = convolution layer의 입력 size와 출력 size 동일
-코드
입력이미지 형태
(이미지 개수, height, width, channel)
filter의 형태
(filter의 height, filter width, filter channel, filter 개수)
- filter가 2개면 작업을 한번 더 한다
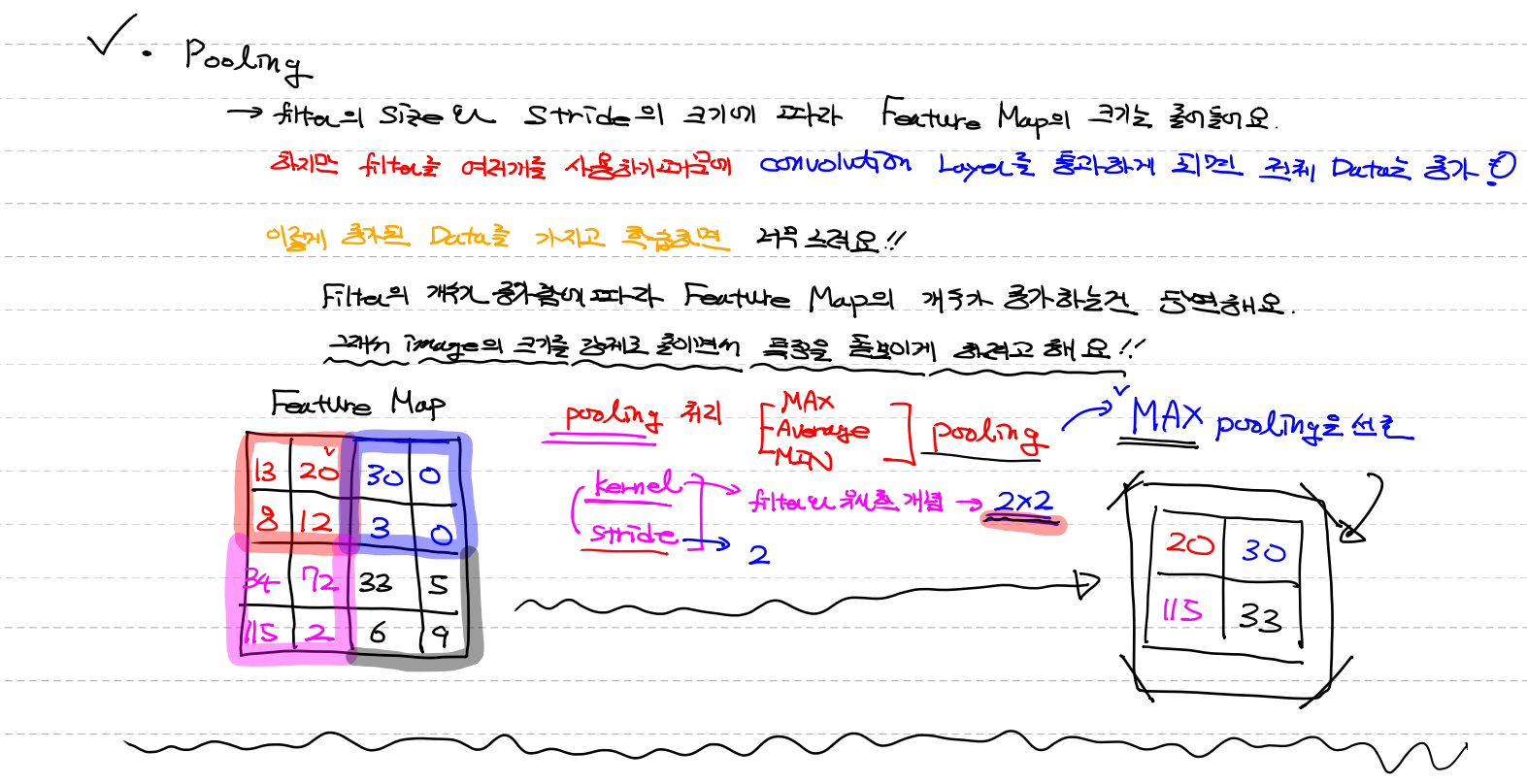
pooling
- conv에서 filter의 크기와 stride의 크기에 따라 feature map의 크기는 줄어들어요
하지만 filter를 여러개를 사용하기때문에 convolution Layer를 통과하게 되면 전체data는 증가
이렇게 증가된 data를 가지고 학습하면 너무느려요 !!
filter의 개수가 증가함에 따라 feature map의 개수가 증가하는건 당연해요.
그래서 image의 size를 강제로 줄이면서 특징을 돋보이게 하려고 해요!!
pooling처리 : kernel과 stride를 이용해서 이미지의 사이즈를 줄인다
왜냐하면 학습 data가 많아지는걸 방지 그래서 선택사항
- Max pooling (default) - 큰값이 더 나은 특징이라 가장 선호
- Average pooling (평균)
- Min pooling
pooling 용어
- kernel : filter와 유사한 개념
- stride
4x4 (feature map) 를 / kernel 2x2 / stride 2 / 의 결과값은 2x2
Drop out : over fitting피해서 model의 accuracy를 높이기 위해 data의 반만 이용
'ai > Deep Learning' 카테고리의 다른 글
| CNN mnist code (0) | 2021.09.29 |
|---|---|
| CNN 전반적 내용 code (0) | 2021.09.29 |
| 이미지 기본 handling 코드 (CNN기초 ver) (0) | 2021.09.17 |
| CNN 기초, 이미지 처리 (0) | 2021.09.17 |
| MNINST (Deep Learning 역사 ver) [he's intializer] (0) | 2021.09.17 |