2021. 8. 28. 00:02ㆍai/Machine Learning

-미분은 machine learning , deep learning에서 빈번하게 사용되요 !!
(빈번히 사용되 기초가 되나 무조건 미분으로만은 아니다)
<기본공식>
- f(x) = constant(상수)
derivative(도함수) = f`(x) = 0
- f(x) = axⁿ
derivaive f`(x) = n * axⁿ- ¹
- f(x) = e(x승)
derivaive f`(x) = e(x승)
- f(x) = e(-x승)
derivaive f`(x) = e(-x승)
- f(x) = in x (자연로그)
derivaive f`(x) = x/1

편미분(partial derivative)
:입력변수가 2개 이상인 다변수 함수에서 미분하려는 변수를 제외한 나머지 변수를
상수로 취급하고 해당변수를 미분하는 방법
f(x) = ~ : 단변수
f(x,y) = ~ : 다변수
ex)




연쇄법칙( chain Rule)
여러함수로 구성된 함수를 "합성함수"라고 해요, 이 합섭함수를 미분할때 chain rule이 이용되요!!


import numpy as np
# 수치미분 최종함수
# 다변수 함수에 대한 수치미분
# 수치미분을 수행할 다변수 함수
# f(x,y) = 2x + 3xy + y^3
# f'(1.0, 2.0) ?? => (8.0, 15.0)
# 1. 수치미분을 수행할 함수
def numerical_derivative(f, x):
# f : 미분을 하려고 하는 함수
# x : 모든 독립변수의 값을 포함하고 있는 ndarray(차원에 무관하게 처리할 수 있어야 해요!)
delta_x = 1e-4
derivative_x = np.zeros_like(x) # [0.0 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index
tmp = x[idx] # x : [1.0 2.0] , tmp = 1.0
# 중앙차분으로 수치미분하는 식 : (f(x + delta_x) - f(x-delta_x)) / 2 * delta_x
x[idx] = tmp + delta_x # x : [1.0001 2.0]
fx_plus_deltax = f(x)
x[idx] = tmp - delta_x # x : [0.9999 2.0]
fx_minus_deltax = f(x)
derivative_x[idx] = (fx_plus_deltax - fx_minus_deltax) / (2 * delta_x)
x[idx] = tmp # x : [1.0 2.0]
it.iternext()
return derivative_x
# 2. 미분할 함수
# 모든 독립변수가 포함된 인자를 하나로 받아서 내부에서 분할해서 처리해야 해요!
def my_func(input_value): # [1.0 2.0]
x = input_value[0]
y = input_value[1]
return 2*x + 3*x*y + np.power(y,3)
#np.power : y의 몇승이냐
# 3. 다변수 함수에 대한 수치미분을 실행
# f'(1.0, 2.0)
result = numerical_derivative(my_func,np.array([1.0, 2.0]))
print(result) # [8.0 15.0]
# 다변수 함수에 대한 수치미분
# 수치미분을 수행할 다변수 함수
# f(a,b,c,d) = 2ab + 3a^2bc + 5cd + 2bd^2
# f'(1.0, 2.0, 3.0, 4.0) ?? => (.. , .. , .. , ..)
# 1. 수치미분을 수행할 함수
def numerical_derivative(f, x):
# f : 미분을 하려고 하는 함수
# x : 모든 독립변수의 값을 포함하고 있는 ndarray(차원에 무관하게 처리할 수 있어야 해요!)
delta_x = 1e-4
derivative_x = np.zeros_like(x) # [0.0 0.0]
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index
tmp = x[idx] # x : [1.0 2.0] , tmp = 1.0
# 중앙차분으로 수치미분하는 식 : (f(x + delta_x) - f(x-delta_x)) / 2 * delta_x
x[idx] = tmp + delta_x # x : [1.0001 2.0]
fx_plus_deltax = f(x)
x[idx] = tmp - delta_x # x : [0.9999 2.0]
fx_minus_deltax = f(x)
derivative_x[idx] = (fx_plus_deltax - fx_minus_deltax) / (2 * delta_x)
x[idx] = tmp # x : [1.0 2.0]
it.iternext()
return derivative_x
# 2. 미분할 함수
# 모든 독립변수가 포함된 인자를 받아서 내부에서 분할해서 처리해야 해요!
# f(a,b,c,d) = 2ab + 6a^bc + 5cd + 2bd^2
def my_func1(input_value): #
a = input_value[0,0]
b = input_value[0,1]
c = input_value[1,0]
d = input_value[1,1]
return 2*a*b + 6*np.power(a,2)*b*c + 5*c*d + 2*b*np.power(d,2)
# 3. 다변수 함수에 대한 수치미분을 실행
# f'(1.0, 2.0)
result = numerical_derivative(my_func1,np.array([[1.0, 2.0],
[3.0, 4.0]]))
print(result) #

Regression(회기) [ 돌아가다 ]
어떤 data에 대해 그 data(아파트가격)에 영향을 주는 조건(지역,층수,학군..)들의 평균적인 영향력을 이용해서
데이터에 대한 조건부평균을 구하는 방법
ex) 어떤 사람이 우리나라 아파트의 시세의 가격 조사한다고 가정
어떻게 해야 우리나라 아파트 시세의 대푯값을 구할수 있을까요 ?
대푯값 을 표현하는 방식들 - 평균(mean), 중위값(중앙값, medium), 최빈값(mode / data중 어떤건 1개 , 어떤건 10개 나오는데 가장 많이나온 값)
평균 - 산술평균(일반적) , 기학평균, 가중평균(가중치를 줘서 평균)
아파트 평균값을 낼때 연도별 추이로 값을 내면 '의미가 있으나' , 일반적인 용도로는 '의미없다'
그이유는 ?? 아파트 가격에 영향을 주는 다양한 요인이 있고 요인에 따라 가격이 천차만별
그래서 유용한 정보가 되려면 다양한 조건에 따른 집계
( 면적,지역,역세권,학권,연식,방향,층수등 ..)을 표로
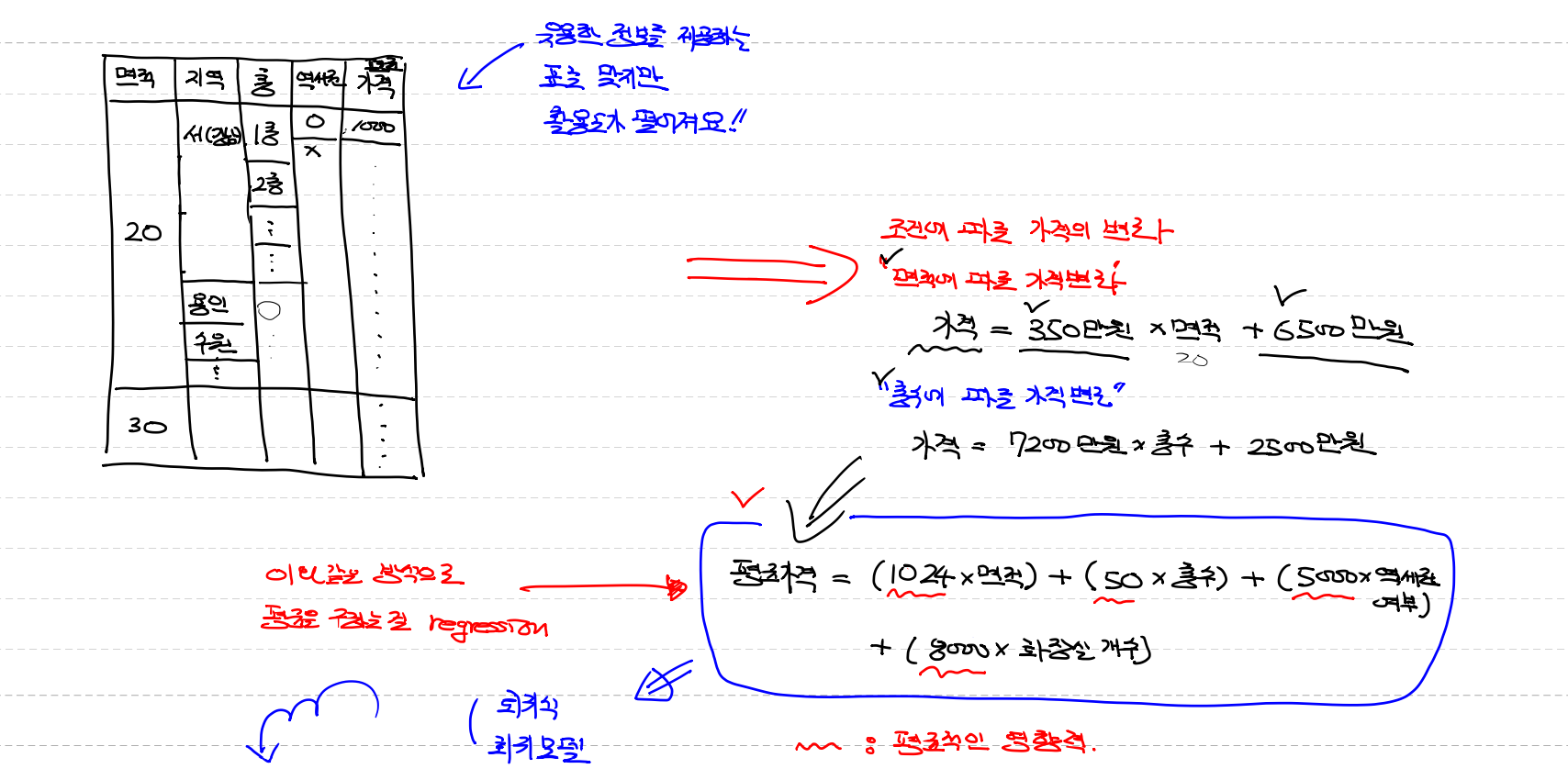
조건에 따른 가격의 변화
-층수에 따른 가격변화 : 가격 = 7200만원 x 층수 + 2500만원
-면적에 따른 가격변화 : 가격 = 350만원 x 면적 + 6500만원
ㅡ>
평균가격 = (1020 x 면적) + (50x층수) + (5000+역세권여부) + (8000 x 화장실 개수)
이와 같은 평균을 구하는걸 회기(regression), 회기식, 회기모델

Regression Model : 어떤 data에 대해 그 값에 영향을 주는 조건들을 고려해서 그 데이터를 가장 잘 표현하는 함수
ex) 독립변수가 1개인 경우 (Classical Linear Regression Model - 선형회기)
y = b(영향을 주는 요인) , x (독립변수)+ 상수값
== / y = ax(기울기) + b(절편) [1차 직선]
평균으로 쓰기 애매한경우가 있다
ex) 우리나라 성인의 남성 키
우리나라 전체 근로자의 연봉
Regression(회기) 의 유래 [ 조건부의 평균을 구하는법 ]
다윈(종의기원 [진화론] ) ㅡ> 사촌형(프란시스 골턴) 이 종의 기원을 읽고 ㅡ>
인간개선목적으로 "우생학(인종을 개선하는 과학)"을 발견 ㅡ> 유전적요인 > 환경 / 이라고 생각 및 조사
→ 키가 큰사람은 아버지보다 크지 않다 / 키가 작은 아버지는 자식이 더 크다 /는걸 발견
→ 키가 점점 전체평균에 근접하는걸 발견하고 논문을 냄 → 평균으로 돌아간다 (Regression toward Mean)
'ai > Machine Learning' 카테고리의 다른 글
| ozone.csv를 python,sklearn으로 LinearRegression 처리 (0) | 2021.08.30 |
|---|---|
| LinearRegression 정리 (0) | 2021.08.30 |
| loss function(손실함수), Gradient Desert Algorithm(경사하강법) (0) | 2021.08.30 |
| 미분 (0) | 2021.08.27 |
| Machine Learning 기본 (2) | 2021.08.25 |