2021. 8. 17. 02:30ㆍpython/pandas, numpy
# 이번에는 Numpy에 대해서 알아보아요!
# python의 numpy module은 Vector(1차원)와 Matrix(2차원)연산에 있어서 상당한 편의성을 제공하는 모듈
# Machine Learning과 Deep Learning의 기본 Module
# ndarray(n-dimensional array) - 데이터타입
# ndarray의 특징
# 1. python의 list와 상당히 유사하게 생겼어요!
# 2. python의 list는 각기 다른 데이터 타입을 저장할 수 있어요! ex) a = [1, True, 'Hello', 3.14]
# 3. ndarray는 동일한 데이터 타입만 사용할 수 있어요!
# 4. list와 상당히 유사하지만 수학적 계산 속도면에서 비교가 불가능할 정도로 ndarray가 빠르고 효율적이예요
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
import numpy as np
b = np.array([1, 2, 3, 4]) # ndarray를 만들어내는 가장 대표적인 방법.
print(type(b)) # <class 'numpy.ndarray'>
print(b) # [1 2 3 4] list와 유사하지만 요소의 구분을 space로 해요!
print(type(b[0])) # <class 'numpy.int32'>
c = np.array([1, 2, 3.14, 4]) #
print(c) # [1. 2. 3.14 4. ]
print(type(c[0])) # <class 'numpy.float64'> 같은 데이터타입이므로
d = np.array([1, 2, 3.14, 4],
dtype=np.int32) # 내가 data type을 명시해줄수 있다 , 특별한 경우가 아니면 float64
print(d) # [1 2 3 4 ]
print(type(d[0])) # <class 'numpy.int32'>
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
import numpy as np
a = [[1, 2, 3], [4, 5, 6]] # 중첩리스트 => 2차원이라고 부르지는 않아요!
b = np.array(a, dtype=np.float64)
print(b) # [[1. 2. 3.]
# [4. 5. 6.]]
print(b[1,1]) # 5.0 [행(가로),열(세로)]
# ndarray의 속성 몇가지만 알아보아요! (기본 대상이 numpy라 np는 빼도된다)
print(b.dtype) # float64
print(b.ndim) # 2 (차원의 수), ndim은 그다지 많이 사용되지 않아요!
print(b.shape) # 결과가 tuple로 나와요! tuple의 요소수가 차원의 개수, (2, 3)
# 안에 숫자가 행관 열을 나타낸다
a = [[[1,2],[3,4]], [[5,6],[7,8]]]
print(np.array(a).shape) # (2, 2, 2)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
import numpy as np
a = [1, 2, 3, 4] # list
arr = np.array(a) # int32형태의 ndarray(vector)가 생성
print(arr) # [1 2 3 4]
print(arr.shape) # (4,)
arr.shape = (2, 2) # 차원을 바꾼다
print(arr) # [[1 2]
# [3 4]]
arr.shape = (4, 1, 1)
print(arr)
print(arr.size) # 4 size는 요소의 개수를 알려줘요!
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
import numpy as np
# data type을 바꾸려면 어떻게 해야 하나요?
a = [1, 2, 3, 4, 5, 6]
arr = np.array(a, dtype=np.float64)
# int32형태의 ndarray로 변경하고 싶으면?? => astype()
result = arr.astype(np.int32)
print(result)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# ndarray를 만드는 또 다른 방법
import numpy as np
* shape은 튜플로 표현되기 때문에 (())
# arr = np.zeros((2,3,3)) # default data type은 np.float64
# 안에 값을 모두 0으로
# print(arr)
# arr = np.ones((2,3)) # 안에 값을 모두 1로
# print(arr)
# arr = np.empty((5,6)) # 빈값이며 , 쓰레기값으로 채워진다, 추후 메모리공간으로 사용
# print(arr)
# arr = np.full((3,4), 9.) #내가 원하는 값으로 채운다 , 보기는 9.로 채운다
# print(arr)
arr = np.array([[1,2,3],[4,5,6]], dtype=np.float64)
result = np.zeros_like(arr) # lile: ~처럼 생긴, 보기는 arr같은 형태를 zoros로 바꾸었다
print(result)
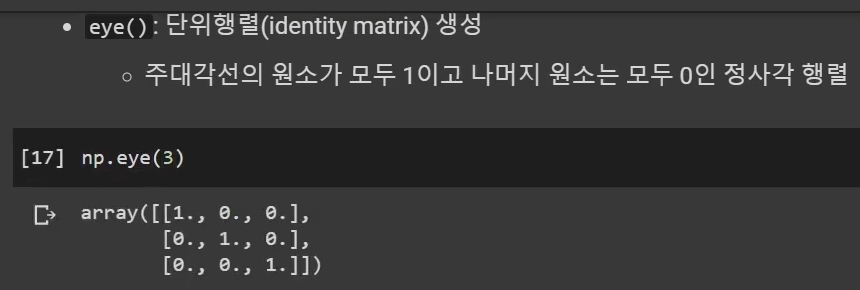
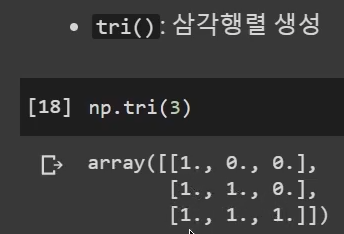
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# numpy array를 생성하는 또 다른 방법
import numpy as np
a = range(0,10,1) # python의 range
print(a)
arr = np.arange(0,10,2) # python의 range와 같은형식
print(arr)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# numpy array를 생성하는 또 다른 방법
import numpy as np
import matplotlib.pyplot as plt
#pyplot을 이용해서 그래프 사용
# np.linspace(start,stop,num)
# start에서 stop까지 범위에서 num개를 균일한 간격으로 원소를 생성하고 배열을 만들어요!
arr = np.linspace(0,10,11)
print(arr)
# 이해하기가 힘들어서 그래프로 그려보아요!
# 그래프를 그리려면 당연히 module을 설치해야 해요! 가장 기반이 되는 module은 matplotlib
# conda install matplotlib
plt.plot(arr, '*')
plt.show()
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
랜덤
# ndarray를 만드는 또 다른 방법 (랜덤하게 생성)
# 5가지 형태로 랜덤하게 ndarray를 생성할 수 있어요!
# numpy설치, matplotlib 설치
# 만약 설치가 잘 안된다.. => 가상환경 자체에 문제가 있을 수 있어요!
# 가상환경을 새롭게 하나 만들어서 필요한 module설치해서 사용해 보아요!
난수 : 정해진 범위 내에서 규칙 없이 만들어진 수 == random
표준편차 : 정규분포 평균값 +-n사이 많은값이 모여있다?
표준 정규분포 : 평균이 0이고 표준편차가 1인 정규분포
정규분포

import numpy as np
import matplotlib.pyplot as plt
# np.random.normal(평균,표준편차,(shape)) : 정규분포 확률밀도함수에서 실수 표본을 추출해서 ndarray를 생성
# 정규분포 그래프를 평균,표준편차 필요
# mean = 50
# std = 2
# arr = np.random.normal(mean,std,(100000,))
# print(arr)
# plt.hist(arr,bins=1000)
histogram : 단위 안에 몇개가 들어가 있는지 표현한 것
bins : 몇개의 영역이 있느냐 즉 그래프가 몇칸이 있느냐
# plt.show()
# np.random.rand(d1,d2,d3,...) : 0 이상 1미만의 균등분포 확률밀도함수에서 실수 표본을 추출해서
# ndarray를 생성 / (인자가 늘어날수록 차원수가 늘어난다, 인자값은 해당 차원의 갯수[shape])
#
# arr = np.random.rand(100000)
# print(arr)
# plt.hist(arr,bins=100)
# plt.show()
# np.random.randn() : 표준 정규분포상에서 실수 표본을 추출해서 ndarray를 생성
# 평균이 0이고 표준편차가 1인 정규분포를 표준정규분포
# randn() 의 n은 normal의 약자
# arr = np.random.randn(100000)
# print(arr)
# plt.hist(arr,bins=100)
# plt.show()
# np.random.randint(low, high, shape) : 최소값과 최대값 사이에서 정해진 shape으로 난수를 추출해서
# ndarray를 생성 => 균등분포를 이용해서 난수(정수) 추출
# arr = np.random.randint(-100, 100, (100000,))
# print(arr)
# plt.hist(arr,bins=100)
# plt.show()
# np.random.random(shape) : 0이상 1미만의 균등분포에서 실수형 난수(random)를 추출해서 ndarray를 생성
*rand와의 차이는 shape이 들어가냐, 사용할때마다 다르기 때문
arr = np.random.random((100000,))
print(arr)
plt.hist(arr,bins=100)
plt.show()
## random값을 이용해서 ndarray를 생성하는 방법!!
###########################################################################################
# 1. python의 list를 이용해서 ndarray생성 => np.array()
# 2. np.ones(), np.zeros(), np.full(), np.empty(), np.ones_like()
# 3. np.arange()
# 4. np.linspace()
# 5. np.random.~~() 랜덤값으로 ndarray를 생성하는 5가지 함수
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
# Numpy 난수 관련 함수
# 난수의 재현(다시 나타난다)성을 확보해보아요!
# 랜덤값(난수) : 컴퓨터의 난수는 알고리즘에 근거해요. 초기값(seed)을 이용해서 특정 알고리즘을 수행시켜서
# 난수값을 도출/ 초기값이 없으면 랜덤값이 계속 바뀌지만 초기값이 잇으면 고정 값은 어떤 수도 상관 없다
import numpy as np
# np.random.seed(3)
# arr = np.random.randint(0,100,(5,))
# print(arr)
(# 데이터의 순서를 바꾸려면 어떻게 해야 하나요?? => shfflue() => ndarray 원본이 변경
# arr = np.arange(0,10,2)
# print(arr)
# np.random.shuffle(arr)
# print(arr) )
# 데이터 집합에서 일부를 무작위로 sampling을 수행하기 위해서 사용하는 choice()
# numpy.random.choice(n, size, replace, p)
# n : ndarray, 혹은 정수가 나오면 arange()를 수행한 결과
# size : sample 개수
# replace=True : 한번 뽑은걸 다시 뽑을 수 있어요! 중복으로 뽑을수 있다라는 뜻
# ndarray => p=[0.1, 0.3, 0, 0.1, 0.1, 0.35, 0.05] 확률
arr = np.array([1,2,3,4,5,6,7])
print(arr)
# arr = np.arange(5)
result = np.random.choice(arr,3, replace=False, p=[0.1, 0.3, 0, 0.1, 0.1, 0.35, 0.05])
print(result)
# 여기까지가 random에 관한 주요한 기능들이예요!
# numpy의 shape관련된 함수
# a = [[1,2,3], [4,5,6]] # python의 중첩리스트
# arr = np.array(a) # ndarray 생성
# print(arr)
# print(arr.shape) # (2,3)
# arr.shape = (3,2)
# print(arr)
### 위의 예처럼 shape속성값을 직접 변경해서 shape을 변경시키는것은 좋지 않아요!
### 대신 제공된 다른 함수를 이용해서 이 작업을 진행해요!
shape 변형할수 있는 함수
arr = np.arange(0,12,1)
print(arr)
result = arr.reshape(4,3) # result는 ndarray가 아니예요! => view
# arr이 원본 result는 데이터를 가지고 있지 않아요!
view : 데이터는 공유하고 있으나 data의 용량 효율성을 위해 보여주기 위한 창문같은 view를 사용
print(result)
result[3,2] = 100
print(result)
print(arr)
reshape 특징
import numpy as np
arr = np.arange(0,12,1)
print(arr) # 요소가 총 12개인 ndarray를 만들었어요!
print(arr.size) # 12
# result = arr.reshape(3,5) # shape이 맞지 않으면 view를 생성할 수 없어요!
# print(result)
# result = arr.reshape(2,-1) # reshape 할때 -1을 적으면 보기에선 무조건 2행을 만든다 단! 1번만 가능
# print(result)
# result = arr.reshape(-1,3)
# print(result)
# result = arr.reshape(2,3,-1)
# print(result)
# result = arr.reshape(3,4) # result는 view가 되요! 데이터를 가지고 있지 않아요!
# print(result)
result = arr.reshape(3,4).copy() # view가 아니라 별도의 ndarray를 만들고 싶어요!
print(result)
arr[0] = 100
print(arr)
print(result)
import numpy as np
a = [[1,2,3], [4,5,6]]
arr = np.array(a)
print(arr)
# 무조건 1차원 ndarray로 변경시키는 함수가 있어요!
result = arr.ravel()
print(result)
# 한가지 기억해야 할 사항은 ravel()로 변경된 결과는 ndarray가 아니라 view예요!
arr[0,0] = 100
print(arr)
print(result)
# resize()
import numpy as np
arr = np.arange(0,12,1)
print(arr)
# result = arr.resize(3,4)
# print(result)
# print(arr)
# result = arr.resize(3,4) # 대상을 return 하지 않고 원본이 변형된다(reshape와의 차이)
# result = np.resize(arr, (3,4)) # np에 resize를 이용하여 view가 아니라 다른 ndarray가 생성되요!
# print(result)
# arr[0] = 100
# print(arr)
# print(result)
result = np.resize(arr, (2,3)) # 행과 열이 달라도 순환해서 채워 가능하기 때문에 resize는 항상 사용에 조심!
print(result) # 가능한한 resize대신에 reshape을 쓰세요!
# 그렇기 때문에 많이 사용하지 않는다
'python > pandas, numpy' 카테고리의 다른 글
| dataframe으로 json이용 (0) | 2021.08.19 |
|---|---|
| pandas 기초 (0) | 2021.08.19 |
| numpy 3일차 (0) | 2021.08.18 |
| numpy 정리 (0) | 2021.08.18 |
| numpy 2일차 (0) | 2021.08.18 |