2021. 8. 23. 15:45ㆍpython/pandas, numpy
# DataFrame의 merge(결합, 합병하다)
# Database의 table의 join과 같은 개념.
import numpy as np
import pandas as pd
data1 = {'학번': [1, 2, 3, 4],
'이름': ['아이유','김연아','홍길동','강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']}
data2 = {'학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
display(df1)
display(df2)

# merge ( inner join ) - 연결점이 있는것만 연결해서 만든다
df3 = pd.merge(df1, df2, on='학번', how='inner')
# 순서가 의미가 있다 어떤게 왼쪽에 나오느냐
#on(~에 대해서 , ~ 를 가지고) = 어떤걸 기준으로 합칠것인지
display(df3)

data2 = {'학번': [1, 2, 4, 1], 일때
1:1 연결이 아니라 colum이 같다면 찾아서 연결

outer join
(잇든 없든 다 합친다) - 즉 연결점이 없어도 결과에 다 포함
# merge ( full outer join )
df3 = pd.merge(df1, df2, on='학번', how='outer')
display(df3)
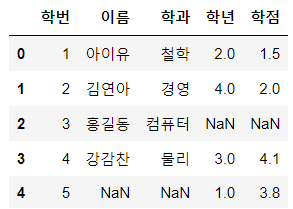
밑 2개의 사진은 제일 상단의 보기와 같다


# merge ( left outer join ) - full outer join에서 left만 포함한다
# df3 = pd.merge(df1, df2, on='학번', how='left')

# merge ( right outer join ) - full outer join에서 right만 포함한다
df3 = pd.merge(df1, df2, on='학번', how='right')

# DataFrame의 merge(결합)
# Database의 table의 join과 같은 개념.
import numpy as np
import pandas as pd
data1 = {'학번': [1, 2, 3, 4],
'이름': ['아이유','김연아','홍길동','강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']}
data2 = {'학생학번': [1, 2, 4, 5],
'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
display(df1)
display(df2)

# merge ( inner join )
# on : 두개의 DataFrame에 공통이름을 가지는 column이 존재할 때
# 만약 DataFrame을 merge시킬 기준이 되는 컬럼의 이름이 다른경우??
df3 = pd.merge(df1, df2, left_on='학번', right_on='학생학번', how='inner')
# 왼쪽은 이거 오른쪽은 이거
display(df3)

하나의 DataFrame의 컬럼과 다른 DataFrame의 index를 기준으로 merge를 하려면 어떻게 해야 하나요?
data2 = {'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]} 와 같이 연결시킬수 있는 colum mergy가 없는 경우

df2 = pd.DataFrame(data2,
index=[1, 2, 4, 5]) 으로 index 변경 (left의 학번을 맞추기 위해)

df3 = pd.merge(df1, df2, left_on='학번', right_index=True, how='inner')

둘다 colum이 아닌 index로도 merge가 가능하다
# DataFrame의 merge(결합)
# Database의 table의 join과 같은 개념.
import numpy as np
import pandas as pd
data1 = {'이름': ['아이유','김연아','홍길동','강감찬'],
'학과': ['철학', '경영', '컴퓨터', '물리']}
data2 = {'학년': [2, 4, 3, 1],
'학점': [1.5, 2.0, 4.1, 3.8]}
df1 = pd.DataFrame(data1,
index=[1, 2, 3, 4])
df2 = pd.DataFrame(data2,
index=[1, 2, 4, 5])
display(df1)
display(df2)

# merge ( inner join )
# on : 두개의 DataFrame에 공통이름을 가지는 column이 존재할 때
df3 = pd.merge(df1, df2, left_index=True, right_index=True, how='inner')
display(df3)

'python > pandas, numpy' 카테고리의 다른 글
| pandas Grouping (0) | 2021.08.23 |
|---|---|
| pandas concat(연결), 결측치, 이상치, 중복행 (0) | 2021.08.23 |
| pandas 공분산, 정렬 (0) | 2021.08.21 |
| pandas 인덱스 와 컬럼(index & colum) (0) | 2021.08.20 |
| dataframe으로 json이용 (0) | 2021.08.19 |